
Gentrace
The LLM evaluation platform for AI teams who care about quality
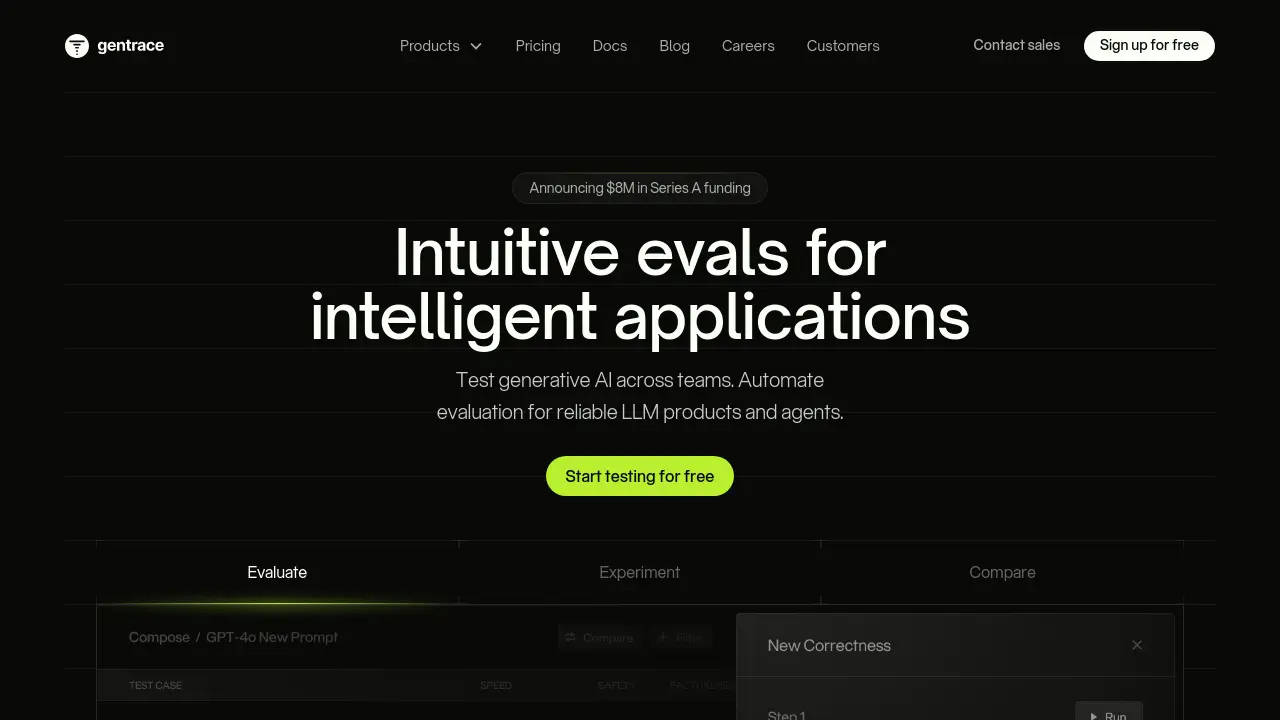
Description
Gentrace provides a collaborative environment specifically designed for testing and evaluating generative AI applications. It addresses common challenges like stale or siloed evaluation pipelines by offering a user interface connected directly to application code. This allows teams, including non-coders, to contribute to writing and managing evaluations, fostering confidence in deploying changes and building reliable LLM products.
The platform facilitates a comprehensive testing workflow, enabling users to manage datasets, run diverse evaluations (LLM-based, code-based, or human), and conduct experiments to optimize prompts, retrieval systems, and model parameters. Gentrace also includes features for monitoring and debugging LLM applications, particularly RAG pipelines and agents, converting evaluation results into shareable reports and dashboards for tracking progress and comparing experiments across different development environments (local, staging, production). It also supports enterprise needs with options for self-hosting and compliance certifications.
Key Features
- Evaluation: Build LLM, code, or human evaluations, manage datasets, and run tests via UI or code.
- Experiments: Conduct test jobs to tune prompts, retrieval systems, and model parameters.
- Reports: Generate dashboards from evaluations to compare experiments and track team progress.
- Tracing: Monitor and debug LLM applications, isolate failures in RAG pipelines and agents.
- Environments: Reuse evaluations consistently across local, staging, and production setups.
- Collaborative UI: Frontend for testing connected to application code, enabling team-wide eval contributions.
- CI/CD Integration: Incorporate evaluations into continuous integration and deployment workflows.
- Self-hosting Option: Available for Enterprise plan users to deploy within their own infrastructure.
- Enterprise Security & Compliance: Offers RBAC, SSO, SCIM, SOC 2 Type II, and ISO 27001.
- Multimodal Output Support: Handles evaluations involving different types of outputs.
Use Cases
- Ensuring quality and reliability of LLM products.
- Facilitating collaborative AI development across engineering and product teams.
- Optimizing prompts, retrieval systems, and model parameters through experimentation.
- Monitoring performance and debugging issues in RAG pipelines and AI agents.
- Standardizing evaluation processes across different development stages.
- Integrating robust AI testing into CI/CD pipelines.
- Scaling generative AI evaluation for enterprise applications.
You Might Also Like

Kome
FreemiumYour all-in-one browser assistant for summarizing, bookmarking, and creating content.

Quizrrito
FreePlay Free Quizzes, Trivia, Games & Explore AI Tools

ChatMyBot
FreemiumAI Chatbot Creator & Live Chat for Facebook, Instagram & Websites

Qayle.ai
FreemiumStop paying to schedule Social Media posts

Synthesis Tutor
Free TrialThe world’s first superhuman AI math tutor.