
/ML
The full-stack AI infra
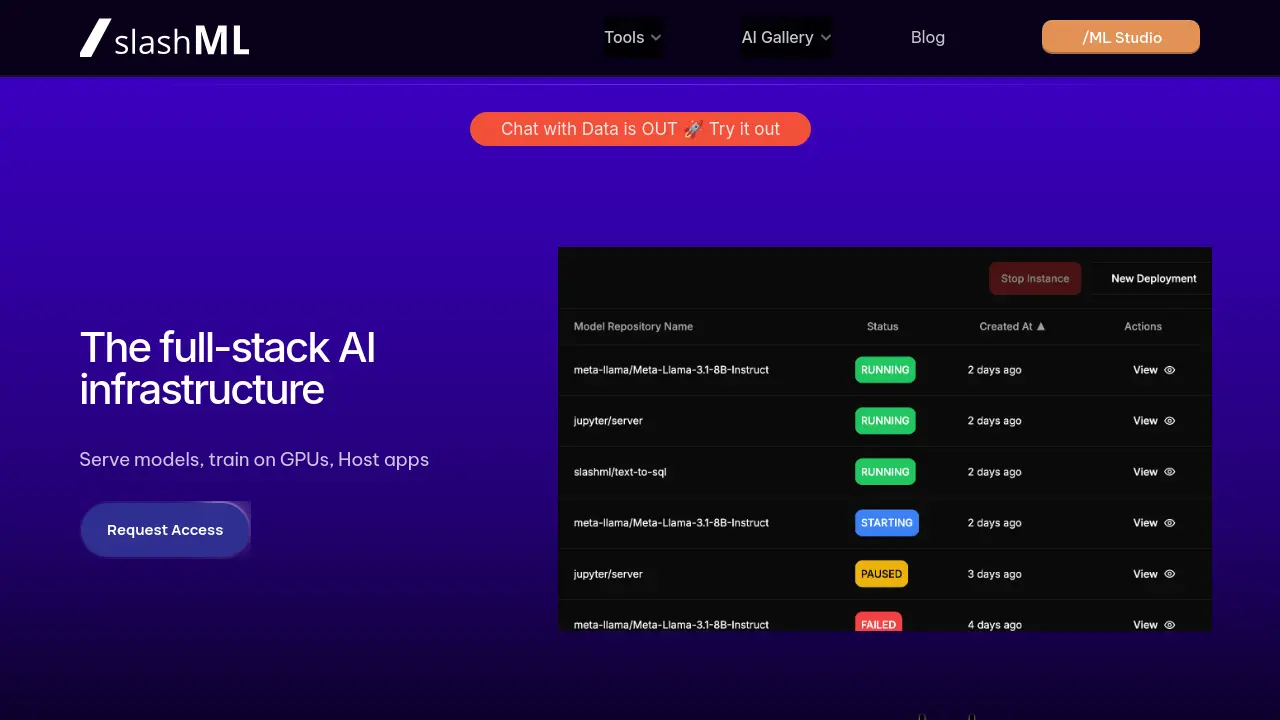
Description
/ML provides a comprehensive full-stack AI infrastructure that empowers users to efficiently serve models, conduct training on GPUs, and host various applications. The platform is built to streamline complex AI workflows by offering Docker and a user-friendly interface for all operations, significantly reducing the time engineers spend on managing configurations.
With /ML, developers can readily serve Large Language Models sourced from Hugging Face. The system also supports the training of multi-modal models, providing the flexibility to use either the platform's integrated /ML Workspaces with provided GPUs or the user's own computational resources. Furthermore, /ML facilitates the hosting of interactive AI applications and dashboards developed with popular frameworks such as Streamlit, Gradio, and Dash, enabling easy sharing with end-users. A key aspect of the platform is its cost observability feature, which offers clear insights into cloud spending associated with AI projects.
Key Features
- Serve Large Language Models: Easily serve LLMs available on Hugging Face with integrated observability.
- Train Multi-modal Models: Train models on /ML Workspaces or your own GPUs, with metrics logging.
- Host AI Applications: Deploy and share Streamlit, Gradio, and Dash applications with monitoring.
- Cost Observability: Gain clear insights into cloud spending and increase cost visibility.
- Docker and UI for Everything: Simplifies configurations and operations, saving development time.
Use Cases
- Deploying and serving pre-trained Large Language Models for various applications.
- Training and fine-tuning multi-modal AI models using dedicated GPU resources.
- Hosting interactive AI-powered dashboards and applications for demonstration or user access.
- Monitoring and optimizing cloud expenditure for AI/ML projects.
- Streamlining AI development and deployment workflows for engineering teams.
Frequently Asked Questions
Why use /ML?
/ML helps you avoid wasting time fighting configurations by providing Docker and a UI for everything, simplifying the process of serving models, training on GPUs, and hosting applications.
You Might Also Like

TempMail
FreeSecure Temporary Email for Online Privacy

GeniusScribe
FreemiumYour Ultimate AI-Powered Writing Partner for Flawless Content Creation.

memoQ
Free TrialTranslation Management System Tailored to Your Needs

Xound
FreemiumClear voice, powerful impact.

Datatruck
Contact for PricingNext Gen Workforce Automation TMS Platform for Transportation