
Synth
The Open Source Data Generator
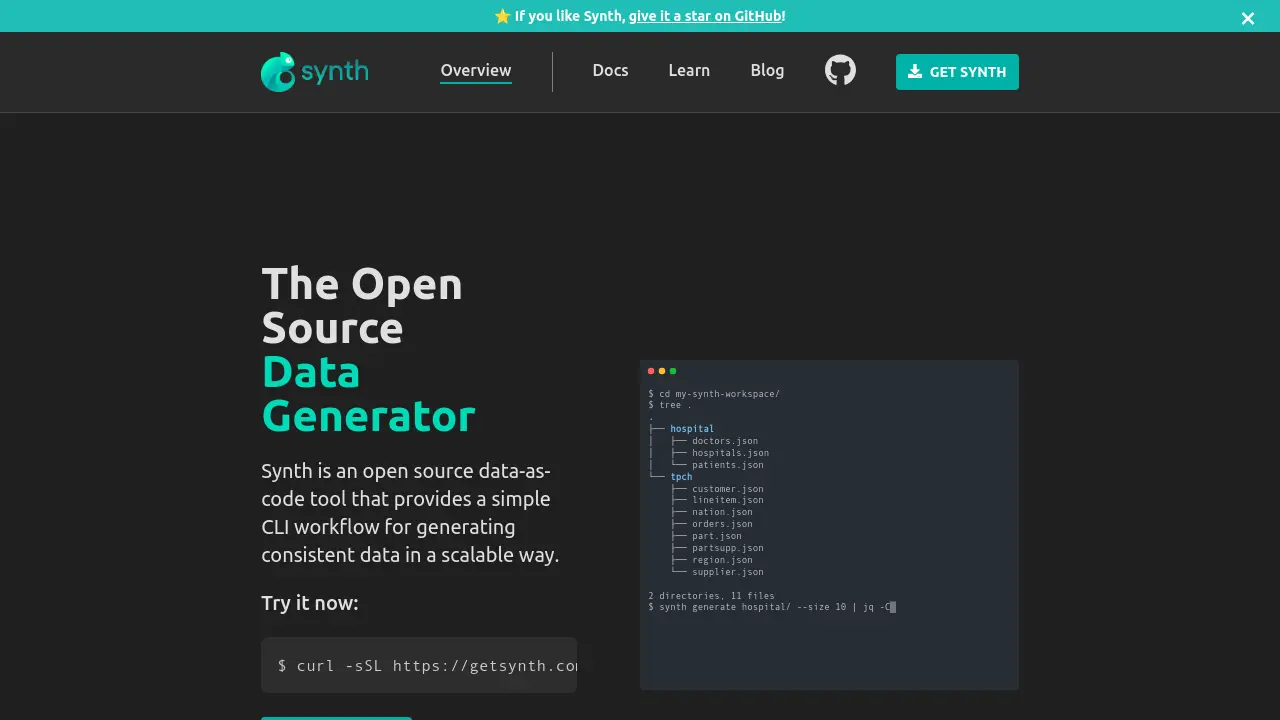
Description
Synth is an open-source data generator designed with a data-as-code philosophy. It utilizes a straightforward command-line interface (CLI) workflow, enabling users to generate consistent data in a scalable manner. The tool facilitates the creation of data models through a declarative configuration language, treating data specifications just like code.
Key capabilities include anonymizing sensitive production data to create realistic yet safe datasets, seeding development and testing environments (including CI pipelines) with appropriate fixtures, and synthesizing custom datasets according to specific constraints, relationships, and semantic requirements. Synth supports easy importing from existing data sources, is database agnostic (compatible with SQL and NoSQL), and can generate data for numerous semantic types like credit card numbers and email addresses.
Key Features
- Open Source: Freely available and community-driven.
- Data as Code: Define data models using a declarative configuration language.
- CLI Workflow: Simple command-line interface for easy operation.
- Easy Imports: Import data schemas directly from existing sources.
- Database Agnostic: Compatible with both SQL and NoSQL databases.
- Semantic Data Types: Supports generation for numerous specific data types (e.g., emails, credit cards).
- Scalable Generation: Designed to generate large volumes of data efficiently.
- Consistent Data Generation: Ensures data adheres to defined rules and relationships.
Use Cases
- Anonymize sensitive production data for safe usage.
- Seed development, testing, and CI environments with realistic data.
- Generate test data fixtures.
- Create custom, realistic datasets based on specific requirements.
- Synthesize data with defined constraints, relations, and semantics.
You Might Also Like

Selli
Free TrialHyper-Personalized Outreach Across Social, Email, and Landing Pages

Charisma.ai
Usage BasedImmersive conversational AI for online training and campaigns

TweetFOX
FreemiumScale the Bird App with the Smartest Twitter Automation Platform.

Pebble
Contact for PricingPebble turns global news, market data and events into actionable portfolio insights—accurately, intuitively, and in real-time.

Migaku
Free TrialTurn Online Content into Language Lessons.